What? 3 posts in 2 days? After months of silence? Isn't it amazing how time flies. Here in the JDeveloper Product Management group we've been busy all year with releases and conferences and many opportunities to get out and talk to people about the great features in our tool. But as the year draws nearer to a close and all the traveling is over I've finally got time to get out on my blog some of the things that I've been evangelizing about all year. As you'll have noticed, one of those is the great new functionality that we've introduced in database modeling.
Periodically I'm asked why we don't introduce a database repository to store database models. One that can be queried and can store versions of the modeled objects? We've been down that road (those of you who've been around for a while know what I'm talking about!) but think that what we have now in JDeveloper is much more flexible. What is it that you want from a repository? Amongst the most important answers to that question is the ability to store multiple versions of your database objects, to query and to compare them.
In previous posts I've demonstrated how you can use our Database Reporting to query your database models and output the results. In this post I want to show you how you can use JDeveloper's integrated versioning system capabilities not only to maintain multiple versions of your database model but how you can resolve any conflicts that arise when multiple users update the model, using a declarative interface.
In this example I am using Subversion (SVN), one of the versioning systems that is integrated in JDeveloper. It is an open source system, widely used in the application development world. I am not going to step through a complete process for versioning in this post, there are various tutorials, how-to, demos. white papers available on
OTN and if you want more information on SVN there is a
very good online book.
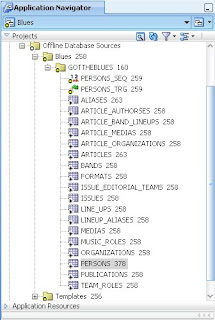
Here is a part of my application. Note that it contains an offline database model (Blues) and one schema (GOTTHEBLUES) containing a number of database objects. This is a project that I'm currently working on. It is stored in an SVN repository - each of the objects has a revision number next to it. Notice that the PERSONS table is at version 378. In SVN the repository revision number is advanced each time a check in of files is done. So this does not mean that the PERSONS table has been checked in 378 times, it shows that the last time PERSONS was checked in the repository moved to version 378. Likewise the last revision of PUBLICATIONS is 258, so PUBLICATIONS has not been changed since revision 258.
If I open PERSONS from the navigator - I get the declarative UI that allows me to edit that object. But that is not how the information is stored. JDeveloper stores its database models by object - in XML. Below is an extract of what you would see if you opened the underlying file PERSONS.table in a browser.
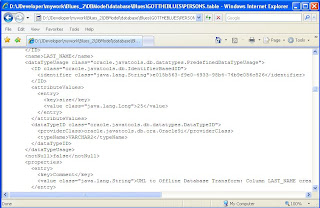
It's not impossible to read - the extract shows the detail for column LAST_NAME, a VARCHAR2 of length 25, with a comment that it was created via a DB Transform (from a class model). However, the declarative UI abstracts you from the raw XML.
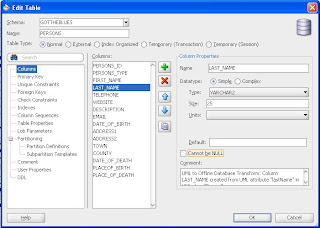
But imagine if you needed to compare two versions of the PERSONS table - or you had two users who were both working on the PERSONS table and checked in their changes to the SVN repository? Comparing the raw XML files is possible, and JDeveloper does recognize XML formating, but in the latest version of JDeveloper (11.1.1.2.0) there is a new declarative UI for that too.
Imagine this scenario: two users have checked out the latest version of the application. SVN uses a copy-modify-merge versioning approach. This means that when an application is checked out a copy of that application is created on the user's local machine. SVN does not keep a record of who and where copies are checked out. It is only interested when something is commited back to the repository. So, as a user I can check out a working copy, make changes to it and if I never commit those changes back to the repository, so be it. I could do some 'what if' type coding and then decide to discard the whole copy.
In my scenario the two users have been discussing the PERSONS table and agree that the length of the LAST_NAME column is too short at 25. Unfortunately, they both decided to modify the column length in their working copy. User 1 happens to be the first to commit her changes back to the repository - so it now has LAST_NAME with a length of 50.
Now user 2 modifies her working copy, editing LAST_NAME to length 40. As good practice dictates, she Updates her working copy with the latest revision from the repository - so she can resolve any code conflicts in her working copy prior to merging her copy back in.
In this case she finds that she has a conflict between her code and the repository that JDeveloper cannot resolve automatically. She sees this in her Application Navigator. It shows the PERSON table with a conflict overlay and the differing versions of the table are also listed (see below)
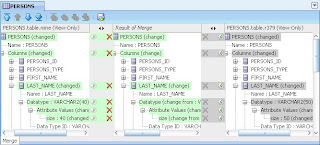
But help is at hand. Double-clicking on PERSONS 379 opens the three-panel Merge window. On the left is her local version of PERSONS - with length 40, on the right is the repository version with length 50. After reviewing this she has shuffled her version into the middle Result of Merge panel. As that was the only conflict in the two files the Save and Complete Merge icon is enabled in the toolbar.
Once she saves this merge and refreshes the Application Navigator the extra conflict files will disappear and the updates will be applied to her working copy. Now she is ready to commit her working copy back to the repository so that it reflects the latest code position.
Not all changes made by multiple users cause conflicts. If the changes are complimentary - for instance one user adds a new column LOCATION and another uses changes the type of PERSONS_TYPE these changes will be added to the repository as SVN and JDeveloper recognize that there is no conflict. This is how SVN works by default, copy-modfy-merge in action. Many systems work this way, and others use the lock-modify-unlock paradigm.
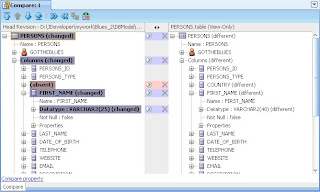
If you want to review changes to a database object prior to updating your working copy, you can use one of the Compare options (Compare with Latest, with Previous, with Other Revision) before you update your working copy with the repository contents. In the example below, user 1 has used Compare with Latest to check her changes: A change to the size of FIRST_NAME and a new column COUNTRY - as shown in the right hand panel with the latest version in the repository (as shown in the left hand panel).
Finally, in this post, a short list of other tips
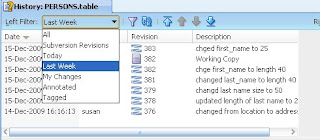
- Using Compare with Other Revision don't forget to scroll to the right - and see not only revision numbers but the commit notes. Also use the filters optimize the revisions listed
- If you make changes to a file but want to revert back to the version you checked out from the repository - use menu Versioning - Revert
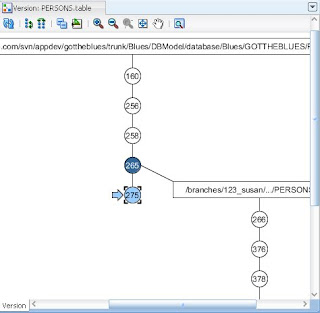
- Use the graphical Version Tree to review branches and versions of your objects
 You could say that having this ability as part of the class model bridges the gap between this model (being used as a logical DB model) and the tranformed physical database model - it provides some form of relative model capability.
You could say that having this ability as part of the class model bridges the gap between this model (being used as a logical DB model) and the tranformed physical database model - it provides some form of relative model capability.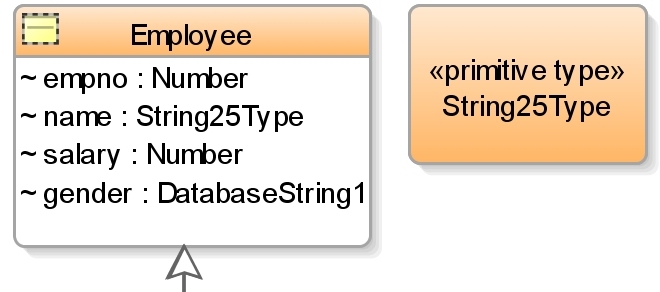 Looking at another new feature in 11.1.2.0, the extract right shows other elements on the class diagram. I've created a primitive type (String25Type) and using the stereotype have specified how this type should be transformed. Now I can use that type on different classes in my diagram and the transformer will use it as necessary.
Looking at another new feature in 11.1.2.0, the extract right shows other elements on the class diagram. I've created a primitive type (String25Type) and using the stereotype have specified how this type should be transformed. Now I can use that type on different classes in my diagram and the transformer will use it as necessary.